Some slides with more info: https://indico.cern.ch/event/1496673/contributions/6637931/a... The approval process for a full paper is quite lengthy in the collaboration, but a more comprehensive one is coming in the following months, if everything went smoothly.
Regarding the exact algorithm: there are a few versions of the models deployed. Before v4 (when this article was written), they are slides 9-10. The model was trained as a plain VAE that is essentially a small MLP. In inference time, the decoder was stripped and the mu^2 term from the KL div was used as the loss (contributions from terms containing sigma was found to be having negliable impact on signal efficiency). In v5 we added a VICREG block before that and used the reconstruction loss instead. Everything runs in =2 clock cycles at 40MHz clock. Since v5, hls4ml-da4ml flow (https://arxiv.org/abs/2512.01463, https://arxiv.org/abs/2507.04535) was used for putting the model on FPGAs.
For CICADA, the models was trained as a VAE again, but this time distilled with supervised loss on the anomaly score on a calibration dataset. Some slides: https://indico.global/event/8004/contributions/72149/attachm... (not up-to-date, but don't know if there other newer open ones). Both student and teacher was a conventional conv-dense models, can be found in slides 14-15.
Just sell some of my works for running qat (high-granularity quantization) and doing deployment (distributed arithmetic) of NNs in the context of such applications (i.e., FPGA deployment for <1us latency), if you are interested: https://arxiv.org/abs/2405.00645 https://arxiv.org/abs/2507.04535
Happy to take any questions.
https://arxiv.org/html/2411.19506v1
Why is it so hard to elaborate what AI algorithm / technique they integrate? Would have made this article much better
I hacked on it a while back, added Comv2dTranspose support to it.
https://www.youtube.com/watch?v=8IZwhbsjhvE (From Zettabytes to a Few Precious Events: Nanosecond AI at the Large Hadron Collider by Thea Aarrestad)
Page: https://www.scylladb.com/tech-talk/from-zettabytes-to-a-few-...
Isn’t this kind of approach feasible for something so purpose-built?
> CERN is using extremely small, custom large language models physically burned into silicon chips to perform real-time filtering of the enormous data generated by the Large Hadron Collider (LHC).
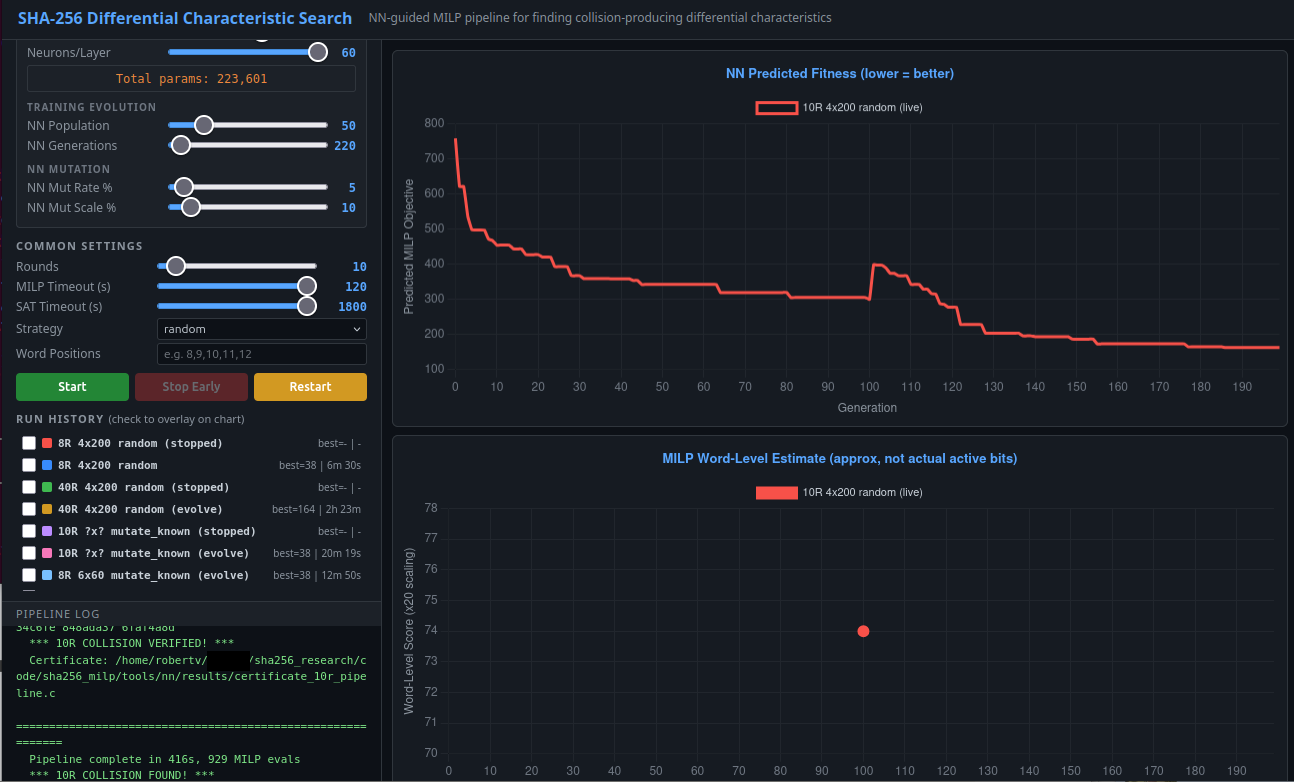
After training it fully, we moved on to the inference stage, trying it on the round counts we didn't have data for! It turned out ... to have zero predictive ability on data it didn't see before. This is on well-structured, sensible extrapolations for what worked at lower round counts, and what could be selected based on real algabraic correlations. This mini neural network isn't part of our pipeline now.
[1] screenshot: https://taonexus.com/publicfiles/mar2026/neural-network.png
{kind=link}